
最近よく耳にするトピックなので自分なりの考察をまとめておきます。書いていくうちに纏まっていくことを願います。
まずそれぞれの定義、言葉の意味を述べておきます。その説明が厳密に、または学術的に正しいかどうかについては専門家ではないので精査しておりませんのであらかじめご了承ください。前提として、「どうやら彼はこういう意味で言葉を用いている」とご理解いただければ幸いです。
機械学習 machine learning : コンピュータサイエンス、AIの一分野。データから学習し課題解決・予測の精度向上を図ること
マーケティング marketing : 市場を創造すること、またはそのための各々の手段・手法
民主化 democratization : 使用や管理権限が、限られた一部の人だけでなく、広く一般的に許されていること
これらをまとめると「機械学習やマーケティングは誰にでもできる」ものになってきている(もちろん学習に要する時間などのコストを忘れてはいけないが)ということ。昨今のAIブームは、決して専門家だけの課題ではない、少なくとも僕ら世代以降とは切り離せないと考えています。
しかし、こう言った話を友人や身内にすると「(とは言うものの)よく分からない・・・」という反応がほとんど。AIに対するイメージが色々あるようで、「ロボットを作るようなことは、研究者の仕事で、自分には全く想像がつかない」と言ったところでしょうか。また、興味を持って勉強を始めても、その第一歩であるプログラミング学習の道もなかなか厳しく数週間から長くても数ヶ月で頓挫する人も多いと思います。極めようと思っても必要な専門知識は膨大なもので、なかなかハードルが高い。。。
これに対する僕のスタンスは「ロボットを作る様な専門家になる必要はないが、どういう原理で動いているのか、基礎的な理解・知識は身につけておくべき」と言うことで、「通訳になる必要はないが、簡単な挨拶やプレゼンが出来れば良い」と言う英語学習に似ています。ただ、より初歩の初歩でつまずき易いのが、プログラミングの難しいところだとも経験する中で感じています。偉そうに書いていますが、僕も長い間この段階で踠いている感じです。
比べて、マーケティングの民主化については先を行っている様に感じます。セグメンテーション・ターゲティング、4P・3C・SWOTなどのフレームワークについては大概の方が聞いたことがあるのではないでしょうか。もし知らなかったとしてもウェブ検索すれば説明ページは山ほどあるし、学習用の動画サイトや勉強会などもすぐ見つかると思います。
その弊害(勝手に自分が考えているだけですが)として、「見えている情報が一緒ならば、みんな答えが一緒になるし、そのアプローチも似てくる」ということ。どの分野にしろ、差別化と言われてもなかなか難しそうです。厳密には製品企画から調達・製造プロセス、流通・プロモーションなど色々な段階で工夫できるので全く同じにはならないですが、均一化の傾向があるということ、今後その様な傾向がより加速していくだろうなとは思います。
話を戻しますと、先ほどの「よく分からない」という機械学習もしくはプログラミング、でもだからこそ「違い」になる。そして、マーケティングとの相性がすごく良いということもポイントだと考えています。
例えば、「今週は雨の日が3日もあるから、仕入れはこれくらいにしよう」など色々な環境・条件から販売を予測することがあると思います。または、「この人の服装から考えると、こういうアレンジを提案すると良いかも」とこれまた予測することがあると思います。当たれば販売増・ロスカット、ブランド強化につながりますし、予測を見誤ればその逆になってしまいます。
こうした予測は個人が行なっていることが多いですが、理論を整理して再現性を高める、他のメンバーが行なっても同レベルの価値を提供できる仕組みを構築するのがマーケティングですし、より複雑な条件「こういう服装だけど、今日は近くのイベントに参加した帰りにお店に来られているから、普段とは雰囲気が違うかも。」といったところまで推測・検証ができる人はいわゆるセンスの良い人なのかもしれません。こうした属人的なノウハウを見える化し、他人が再現できる様にするのは手間暇が掛かりますし、その時々の業務量や受けて・伝える側、それぞれ個人のキャパシティに依存することも多く、なかなか難しいというところではないでしょうか。
しかし、お気付きになられたかもしれませんが、「データから学習し、課題解決・予測の精度向上を図ること」という機械学習の定義は、まさしくこの様なマーケティングの作業と似ているということ。これはやって見ると実感することですが、コンピューターの方がその検証はかなり早くできますし、膨大な組み合わせにも対処しやすい。だからと言って、ビッグデータといわれる様な何万、何億というデータセットがなくとも、身近な記録から当たりをつけていくことが大切なのではないか。そういう地道な改善を積み上げて、お客様の期待に応え続けられる様にするのがマーケッターであり、経営者なのではないか。そう考えて精進していかなければと自分に言い聞かせている今日この頃です。
前段が長くなりましたが、実際にどういうことについて話をしているんだというのは見てもらう方が分かりやすいのではないかと思うので、python のライブラリである scikit-learn のデータセット、iris (アヤメ)を少し分析して見たいと思います。全行程説明となると、超超長文になるので、今回はスタート部分まで。プログラミングだけについて書きたい、話したいのではなく、タイトルのテーマについて考えを深めることが目的ですので、コードなど詳細は省略、専門のページにお任せします。こちらについてもあらかじめご理解お願いします。
機械学習 machine learning : コンピュータサイエンス、AIの一分野。データから学習し課題解決・予測の精度向上を図ること
マーケティング marketing : 市場を創造すること、またはそのための各々の手段・手法
民主化 democratization : 使用や管理権限が、限られた一部の人だけでなく、広く一般的に許されていること
これらをまとめると「機械学習やマーケティングは誰にでもできる」ものになってきている(もちろん学習に要する時間などのコストを忘れてはいけないが)ということ。昨今のAIブームは、決して専門家だけの課題ではない、少なくとも僕ら世代以降とは切り離せないと考えています。
しかし、こう言った話を友人や身内にすると「(とは言うものの)よく分からない・・・」という反応がほとんど。AIに対するイメージが色々あるようで、「ロボットを作るようなことは、研究者の仕事で、自分には全く想像がつかない」と言ったところでしょうか。また、興味を持って勉強を始めても、その第一歩であるプログラミング学習の道もなかなか厳しく数週間から長くても数ヶ月で頓挫する人も多いと思います。極めようと思っても必要な専門知識は膨大なもので、なかなかハードルが高い。。。
これに対する僕のスタンスは「ロボットを作る様な専門家になる必要はないが、どういう原理で動いているのか、基礎的な理解・知識は身につけておくべき」と言うことで、「通訳になる必要はないが、簡単な挨拶やプレゼンが出来れば良い」と言う英語学習に似ています。ただ、より初歩の初歩でつまずき易いのが、プログラミングの難しいところだとも経験する中で感じています。偉そうに書いていますが、僕も長い間この段階で踠いている感じです。
比べて、マーケティングの民主化については先を行っている様に感じます。セグメンテーション・ターゲティング、4P・3C・SWOTなどのフレームワークについては大概の方が聞いたことがあるのではないでしょうか。もし知らなかったとしてもウェブ検索すれば説明ページは山ほどあるし、学習用の動画サイトや勉強会などもすぐ見つかると思います。
その弊害(勝手に自分が考えているだけですが)として、「見えている情報が一緒ならば、みんな答えが一緒になるし、そのアプローチも似てくる」ということ。どの分野にしろ、差別化と言われてもなかなか難しそうです。厳密には製品企画から調達・製造プロセス、流通・プロモーションなど色々な段階で工夫できるので全く同じにはならないですが、均一化の傾向があるということ、今後その様な傾向がより加速していくだろうなとは思います。
話を戻しますと、先ほどの「よく分からない」という機械学習もしくはプログラミング、でもだからこそ「違い」になる。そして、マーケティングとの相性がすごく良いということもポイントだと考えています。
例えば、「今週は雨の日が3日もあるから、仕入れはこれくらいにしよう」など色々な環境・条件から販売を予測することがあると思います。または、「この人の服装から考えると、こういうアレンジを提案すると良いかも」とこれまた予測することがあると思います。当たれば販売増・ロスカット、ブランド強化につながりますし、予測を見誤ればその逆になってしまいます。
こうした予測は個人が行なっていることが多いですが、理論を整理して再現性を高める、他のメンバーが行なっても同レベルの価値を提供できる仕組みを構築するのがマーケティングですし、より複雑な条件「こういう服装だけど、今日は近くのイベントに参加した帰りにお店に来られているから、普段とは雰囲気が違うかも。」といったところまで推測・検証ができる人はいわゆるセンスの良い人なのかもしれません。こうした属人的なノウハウを見える化し、他人が再現できる様にするのは手間暇が掛かりますし、その時々の業務量や受けて・伝える側、それぞれ個人のキャパシティに依存することも多く、なかなか難しいというところではないでしょうか。
しかし、お気付きになられたかもしれませんが、「データから学習し、課題解決・予測の精度向上を図ること」という機械学習の定義は、まさしくこの様なマーケティングの作業と似ているということ。これはやって見ると実感することですが、コンピューターの方がその検証はかなり早くできますし、膨大な組み合わせにも対処しやすい。だからと言って、ビッグデータといわれる様な何万、何億というデータセットがなくとも、身近な記録から当たりをつけていくことが大切なのではないか。そういう地道な改善を積み上げて、お客様の期待に応え続けられる様にするのがマーケッターであり、経営者なのではないか。そう考えて精進していかなければと自分に言い聞かせている今日この頃です。
前段が長くなりましたが、実際にどういうことについて話をしているんだというのは見てもらう方が分かりやすいのではないかと思うので、python のライブラリである scikit-learn のデータセット、iris (アヤメ)を少し分析して見たいと思います。全行程説明となると、超超長文になるので、今回はスタート部分まで。プログラミングだけについて書きたい、話したいのではなく、タイトルのテーマについて考えを深めることが目的ですので、コードなど詳細は省略、専門のページにお任せします。こちらについてもあらかじめご理解お願いします。

全部で150のデータがあって、50ずつ3つの種類のアヤメに関するデータが集められている。それぞれのデータには (1)萼(がく)の長さ、(2)萼の幅、(3)花弁の長さ、(4)花弁の幅が記載されている。加えて、それぞれの種類に関する情報も別で記載されており、 機械学習では前者の情報から後者の種類を推測すると言うことが目的です。ちなみにグループ(class)は、 'Setosa ひおうぎあやめ (檜扇菖蒲)', 'Versicolour ブルーフラッグ', 'Virginica *情報見つかりませんでした'があります。
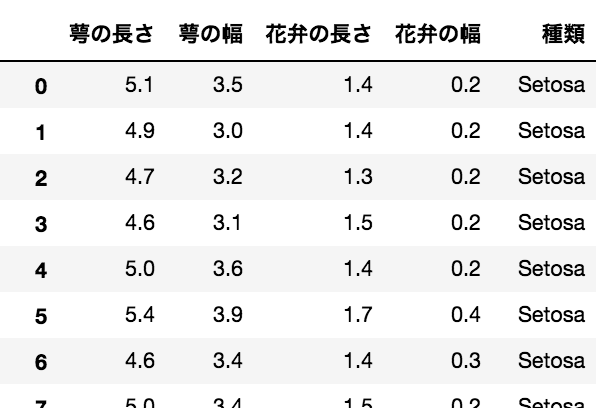
実際のデータの中身を眺めるとこんな感じで、150個の個体に関するデータが cm で記載されています。これだけでは分類ができないのでグラフを作って詳細を確認していきます。
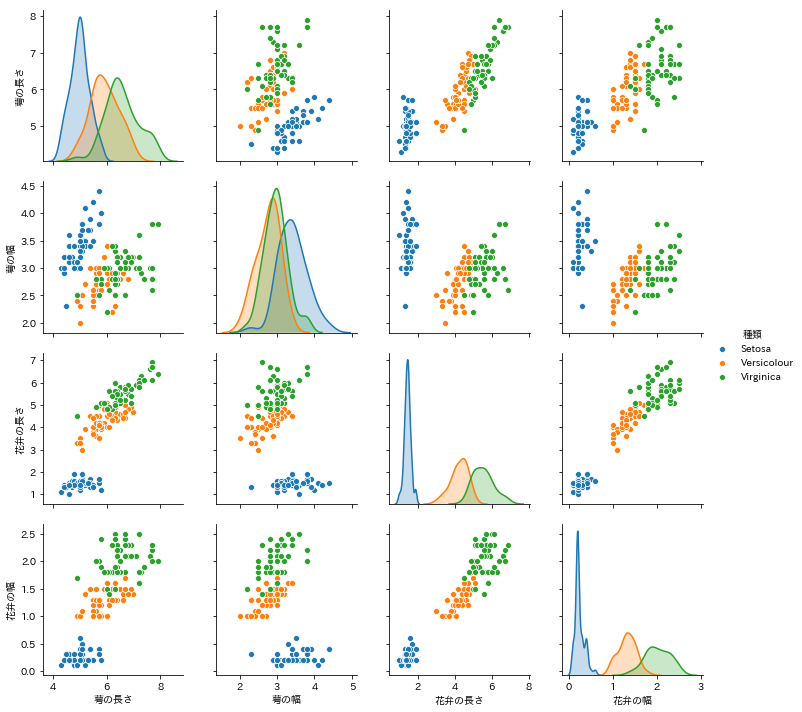
ずらっーーーと 4*4 =16 のグラフが並んでいますが、これは縦横で先ほどの4つのデータを掛け合わせて、種類ごとに色分けをしたグラフの集合です。例えば一番左の列の2行目のグラフは、縦軸に萼の幅、横軸に萼の長さを取っています。対角線上にある山なりのグラフは縦軸、横軸に同じデータを当てはめた場合のグラフです。この作図作業が1行のコードで出来てしまうと知った時は驚きでしたし、"民主化"と煽っているのもそう言う感動から来ています。話がそれました。
データ分析を徹底的にやりたいなら、一つ一つを読み解き仮説を立てて、別のグラフを作図していく必要があると思うのですが、「パッと見てこれはどの種類だ」と判別するだけならば、これだけでも十分かもしれません。対角線に並ぶグラフの下から2つのグラフを見ると、種類どうしが重なる部分が少ないことが分かります。よって「花弁の長さが2cm以下なら Setosaだな」、「幅が2cm以上だからVirginicaだ」と花弁に注目すると種類が分かりやすいと言うことが発見できました。少なくともStosa は花弁をチェックすれば他の2種類と区別できそうです。
このデータが天気であったり、価格であったり、来店回数であったり、自身の活動や業務に置き換えて見ると、色々応用できそうじゃありませんか?(と言ってみましたが、なかなか他人に説明するのは難しいので、トライしていきたいと思います。ぜひ興味があれば詰まっている僕に質問してみてください。)
とは言うものの重なっている部分の個体はどう判断するの?と言う様な疑問がまだまだ残るので、次回以降、より正確な分類(決定木とか)を試してみたいと思います。
*書いていくうちに纏まっていくことを願いましたが、どうやら叶わなかった様です。次回以降に改善できる様に頑張ります。
<2018.12.20 追記>
上記決定木の分析についてブログ「わからない問題を前に立ち止まるか、少しでも工夫して何かを学ぼうとするか」を書きました。ご興味のある方はぜひこちらもご確認ください。
データ分析を徹底的にやりたいなら、一つ一つを読み解き仮説を立てて、別のグラフを作図していく必要があると思うのですが、「パッと見てこれはどの種類だ」と判別するだけならば、これだけでも十分かもしれません。対角線に並ぶグラフの下から2つのグラフを見ると、種類どうしが重なる部分が少ないことが分かります。よって「花弁の長さが2cm以下なら Setosaだな」、「幅が2cm以上だからVirginicaだ」と花弁に注目すると種類が分かりやすいと言うことが発見できました。少なくともStosa は花弁をチェックすれば他の2種類と区別できそうです。
このデータが天気であったり、価格であったり、来店回数であったり、自身の活動や業務に置き換えて見ると、色々応用できそうじゃありませんか?(と言ってみましたが、なかなか他人に説明するのは難しいので、トライしていきたいと思います。ぜひ興味があれば詰まっている僕に質問してみてください。)
とは言うものの重なっている部分の個体はどう判断するの?と言う様な疑問がまだまだ残るので、次回以降、より正確な分類(決定木とか)を試してみたいと思います。
*書いていくうちに纏まっていくことを願いましたが、どうやら叶わなかった様です。次回以降に改善できる様に頑張ります。
<2018.12.20 追記>
上記決定木の分析についてブログ「わからない問題を前に立ち止まるか、少しでも工夫して何かを学ぼうとするか」を書きました。ご興味のある方はぜひこちらもご確認ください。