
前回の続きと作業しながら考えたこと。
*前記事(機械学習の民主化とマーケティングについて思うこと)はこちらからご確認頂けます。
始めに、これまでに書いたことを簡単に整理します、
・機械学習によるデータの見える化・意思決定の重要性が今後ますます上がっていく
・例として、iris (アヤメ)のデータセットを使用、分析
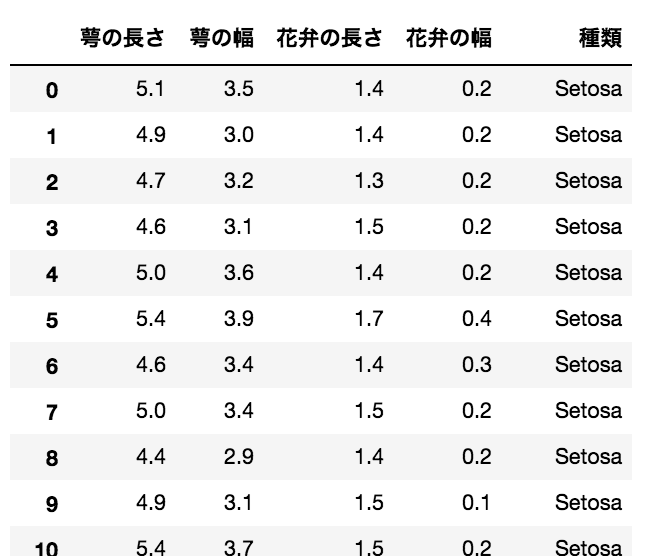
・そのデータ詳細は下記の様に、萼と花弁について cm サイズとそれぞれの花の種類(アヤメの中での分類)が記載されている
始めに、これまでに書いたことを簡単に整理します、
・機械学習によるデータの見える化・意思決定の重要性が今後ますます上がっていく
・例として、iris (アヤメ)のデータセットを使用、分析
・そのデータ詳細は下記の様に、萼と花弁について cm サイズとそれぞれの花の種類(アヤメの中での分類)が記載されている
・それぞれの値を縦横軸に当てグラフ化をし、”「花弁の長さが2cm以下なら Setosaだな」、「幅が2cm以上だからVirginicaだ」と花弁に注目すると種類が分かりやすい”という簡単な判断をするところまで至った。
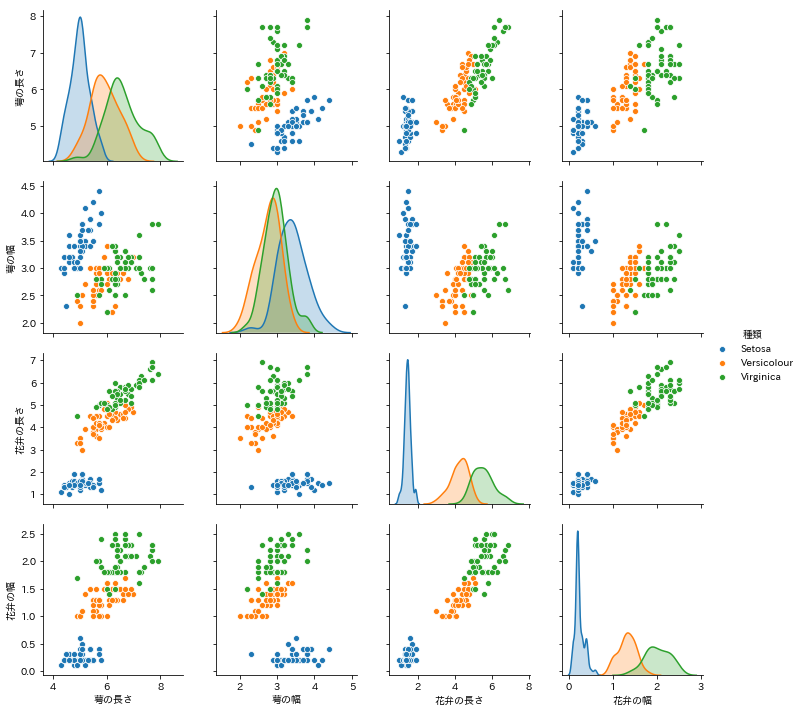
ザッと見て大まかな判断をする場合これで構わないと思いますが、より正確に早く(=扱うデータの量も大きく)するならば、機械学習・プログラミングがさらに力を貸してくれます。今回は中でもシンプルでロジックが図示出来た決定木(分類木)を使用します。
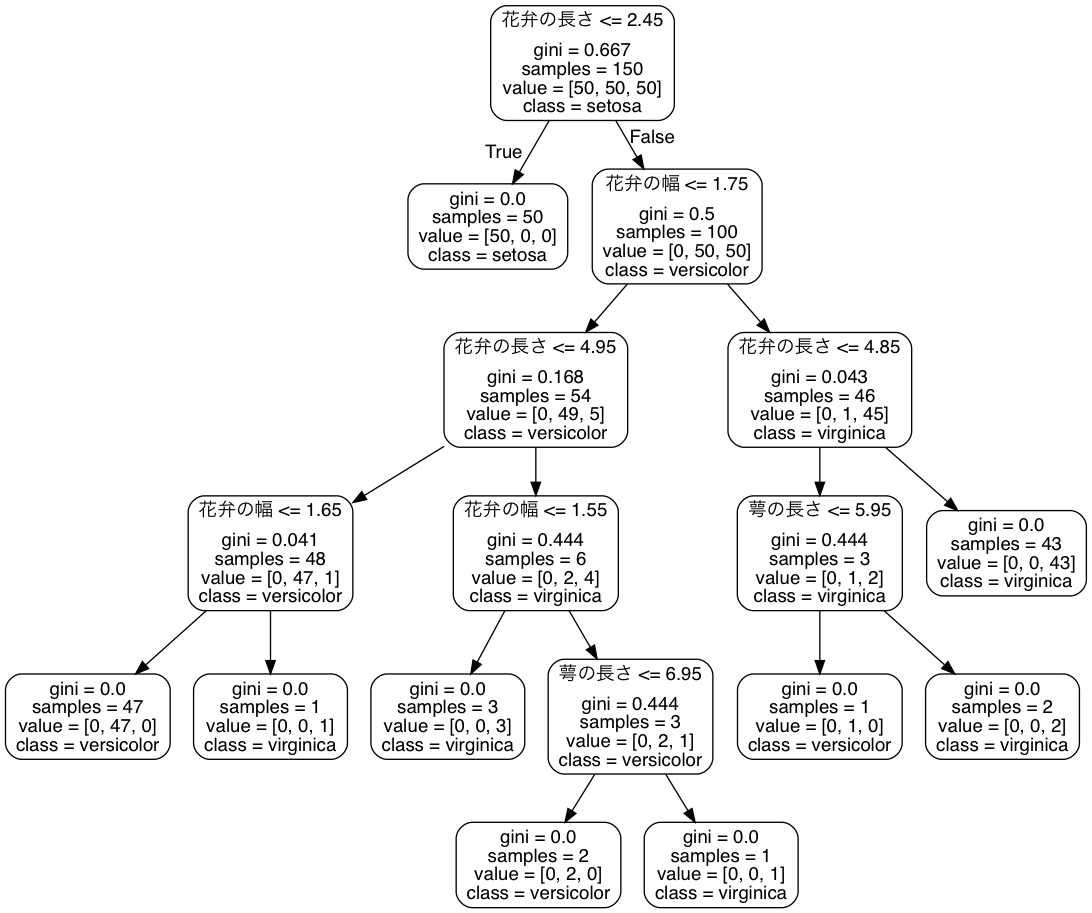
ズラーッと四角が並んでいて正直面倒な感じもしますが(概要理解まで、全部理解する必要はない気もします)、これが決定木です。
⑴各囲いの中の一番上、例えば”花弁の長さ<=2.45”と書かれた部分、それと⑵下に分岐する矢印(左が⑴の条件に当てはまる、右が条件に当てはまらない)の2点を確認するとわかりやすいです。
上述の通り、私は花弁の長さ2.0cmを基準としましたが、ここでは2.45cmまでとなっています。その条件に合致する場合、一つ下の段の左側に行って、setosa(総サンプル150のうち、50がこれに該当する) であるという判断がされます。バクッとグラフで当たりをつけていた場合、2.3cmの物の判断が間違っていた場合がありますが、ここではそれを防ぐことができました。(実際には花の色だったり、もっと総合的な判断になると思いますが、機械学習の紹介記事ということで、そうしたところの精査はファジーなままでご容赦ください。)
⑴の条件に合わなかった場合、右の囲いに移動して次の条件”花弁の幅が1.75cm以下かどうか”を調べます。下のグラフでいうと縦軸の数値がその目安です。
⑴各囲いの中の一番上、例えば”花弁の長さ<=2.45”と書かれた部分、それと⑵下に分岐する矢印(左が⑴の条件に当てはまる、右が条件に当てはまらない)の2点を確認するとわかりやすいです。
上述の通り、私は花弁の長さ2.0cmを基準としましたが、ここでは2.45cmまでとなっています。その条件に合致する場合、一つ下の段の左側に行って、setosa(総サンプル150のうち、50がこれに該当する) であるという判断がされます。バクッとグラフで当たりをつけていた場合、2.3cmの物の判断が間違っていた場合がありますが、ここではそれを防ぐことができました。(実際には花の色だったり、もっと総合的な判断になると思いますが、機械学習の紹介記事ということで、そうしたところの精査はファジーなままでご容赦ください。)
⑴の条件に合わなかった場合、右の囲いに移動して次の条件”花弁の幅が1.75cm以下かどうか”を調べます。下のグラフでいうと縦軸の数値がその目安です。
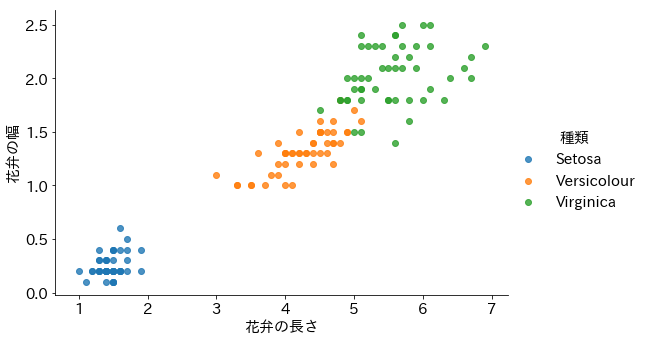
こうしたガイドに従って、最終的に与えられたデータからこれはどの種類のアヤメか判断をしていきます。ちなみにサンプルデータに対するこの分岐(決定木)の正解率は100%となりました。なかなかすごいんじゃないかと自画自賛?(プログラミングでやっているので、自分でやったと言っていいのか?と感じる)してしまいます。
今回は分類をしましたが、詳細な数値の予測なども出来るようなので、そうした手法もどんどん勉強したいと思います。まだまだアイデア段階ですが、データ分析から体調管理や病気の予防に関する考察、販売予測など色々な応用が効くと感じます。周りに伝えていくことで何か新しいことが始められればと思います。
今回は分類をしましたが、詳細な数値の予測なども出来るようなので、そうした手法もどんどん勉強したいと思います。まだまだアイデア段階ですが、データ分析から体調管理や病気の予防に関する考察、販売予測など色々な応用が効くと感じます。周りに伝えていくことで何か新しいことが始められればと思います。
ここからは少し抽象的な話、でもタイトルに繋がることについて書きたいと思います。
先ほど正解率100%と書きましたが、これは自慢が目的ではなく前振りで、あくまで「サンプルのデータセットに対する分析力が優れているだけ」で、未知のデータを与えられた場合はそうじゃないということを忘れてはいけないと思います。
例えば、同じcmで記載された4つのデータだったとしても、いたずらで僕の顔の長さ・幅、首の長さ・幅を提示したとします。全く iris とは関係がありませんが、今のプログラムコードは3種類のアヤメのどれかだと判断します。失笑してしまうくらい、全くもって0点ですよね。(もっと良い例あると思いますが、わかりやすく極端な例にしました)
「これは松本のサイズ、アイリスとは関係ない」だから「判断をしない」もしくは「人間のサイズという新しいクラス(種類)を追加する」と教えない限り、その誤った判断を繰り返します。その後、また違うデータを与えれば、同じ様に判断基準を入力しなければいけません(厳密には大量膨大なデータを自動で学習し続けるディープラーニングの様な手法もありますが、ここではプログラミングの概要、対する僕の所感をわかりやすくするため、ここまでの掘り下げとさせてください)
要約すると「機械・プログラムは、未知の問題に直面した際、管理者(もしくは編集権限者など)の指示があるまで待つ、もしくは精度の悪い判断に終始するかもしれない」ということが今回の作業での気付きであり、メッセージです。
AIやIOTの普及で「人間とは何か」が問われる中で、機械と同じ様にストップしてしまうのでは駄目でしょう。わからない問題に出くわした際、五感を働かせ、他人と協働し、何らかの仮説を元に先に一歩踏み出すことが出来るのが人間じゃないかと思います。その結果大概失敗するし、時には成功することもあるでしょう。
大事なのは、そこから得た学びをプログラムとして成立させ学習し、自分はまた新しい試みへと進んでいくことだと強く感じます。
いろんな課題やしがらみも社会にはある、そんな簡単に言い切れるものではないということは承知しています。が、そうした感情も含め、色々な波を感じることができることも、人間の楽しさなのかなぁと思います。この橋渡しが大切です。
先ほど正解率100%と書きましたが、これは自慢が目的ではなく前振りで、あくまで「サンプルのデータセットに対する分析力が優れているだけ」で、未知のデータを与えられた場合はそうじゃないということを忘れてはいけないと思います。
例えば、同じcmで記載された4つのデータだったとしても、いたずらで僕の顔の長さ・幅、首の長さ・幅を提示したとします。全く iris とは関係がありませんが、今のプログラムコードは3種類のアヤメのどれかだと判断します。失笑してしまうくらい、全くもって0点ですよね。(もっと良い例あると思いますが、わかりやすく極端な例にしました)
「これは松本のサイズ、アイリスとは関係ない」だから「判断をしない」もしくは「人間のサイズという新しいクラス(種類)を追加する」と教えない限り、その誤った判断を繰り返します。その後、また違うデータを与えれば、同じ様に判断基準を入力しなければいけません(厳密には大量膨大なデータを自動で学習し続けるディープラーニングの様な手法もありますが、ここではプログラミングの概要、対する僕の所感をわかりやすくするため、ここまでの掘り下げとさせてください)
要約すると「機械・プログラムは、未知の問題に直面した際、管理者(もしくは編集権限者など)の指示があるまで待つ、もしくは精度の悪い判断に終始するかもしれない」ということが今回の作業での気付きであり、メッセージです。
AIやIOTの普及で「人間とは何か」が問われる中で、機械と同じ様にストップしてしまうのでは駄目でしょう。わからない問題に出くわした際、五感を働かせ、他人と協働し、何らかの仮説を元に先に一歩踏み出すことが出来るのが人間じゃないかと思います。その結果大概失敗するし、時には成功することもあるでしょう。
大事なのは、そこから得た学びをプログラムとして成立させ学習し、自分はまた新しい試みへと進んでいくことだと強く感じます。
いろんな課題やしがらみも社会にはある、そんな簡単に言い切れるものではないということは承知しています。が、そうした感情も含め、色々な波を感じることができることも、人間の楽しさなのかなぁと思います。この橋渡しが大切です。